One of the distinct work packages during the design and implmentation of the database that will sit within the main ArchAIDE application has been the creation of mulitlingual vocabularies to aid cross-searching catalogues that differ both linguistically, but also conceptually. To take the simplified example above, we may not only use different words within our own laguage to categorise something, but based on our respective archaeological traditions we may use different levels of granularity which have become firmly established in our working practices. For example, I may simply call something a "plate", but someone else may wish to call it a "dinner plate". Ultimately, we 're talking about a shared concept, and in searching a database I may not want to be presented with too many classifications, or to miss the detail in other people's data.
At the time of writing vocabularies have been created for a series of fields within the database that would normally use a controlled list:
- Sherd type (for example "rim" or "handle")
- Form (for example "plate" or "urn")
- Decoration form (for example "Burnished" or "incised")
- Decoration color (for example "yellow")
- Fabric (in progress!)
Each of the partners (Cologne, York, Pisa and Barcelona) that are contributing data to the reference database have gone through their inventories and catalogues, and identified the descriptive terms used within that refer to those main categories. Learning from the methodology and using the tools developed for the ARIADNE project by the Hypermedia Research Group at the University of South Wales, we've then looked to create a neutral spine to which partners could map these terms. The ARIADNE project used the Getty Research Institutes's Art and Architecture Thesaurus (AAT) to successfully map all the resource discovery subjects but it was not known whether the AAT would be suitable for the for more specialised pottery concepts. After a thorough evaluation, it was decided it was immensely useful in this regard, and would give the added value of interoperability with ARIADNE and any other data mapped to the AAT. To give a very basic example, after consultation it was decided that the AAT concept sgraffito was adequate to describe the form of decoration made by scratching through a surface to reveal a lower layer of a contrasting colour.
In Italian catalogues the following terms are used to describe this technique, :
- graffita
- graffita a punta
- graffita a stecca
In Spanish + Catalan catalogues:
Thus all these terms were mapped to sgraffito. Within the reference database, any data being imported that contains, for example 'graffita a stecca' could extend the section on decoration form to also contain the AAT term.

Besides having a centralised term that can be used to provide a simple linguistic transaltion (so a Spanish user looking for types of 'Esgrafiada' will find all the 'graffita...') there are further benefits to this approach. The first is for simple knowledge organisation within our own database. So, for example in the photograph (right) from the Roman Amphorae database, the image depicts only part of the vessel. We can use the selected AAT terms to describe the parts depicted, e.g.:
Thus we now know that that picture contains a series of solid, defined concepts
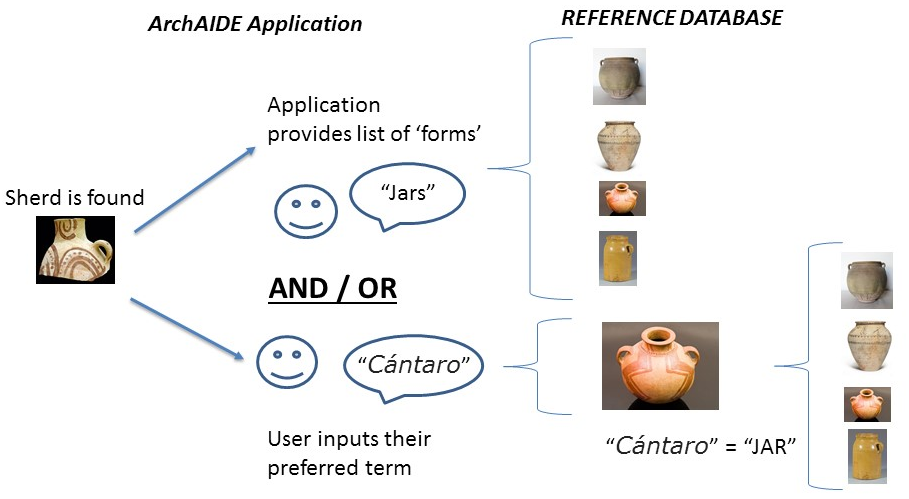
Now, in a hypothetical scenario. Someone in the field may find a sherd of pottery to run through the ArchAIDE application (below, right). In this case they will be presented with a list of neutral terms with which to categorise it:

If the user can make a firm identification, they would probably deduce that this sherd could probably be classed as belonging to handles!
Alternatively, the user could opt to select or input terms in their own language. For example to show just a few terms from the German vocabulary:
- gebogener Henkel
- Ohrförmiger Henkel
- langer Vertikalhenkel
Again, these are all types of handles! So, right from the beginning we can start filtering our database, and looking for models that contain handles for comparison. This would of course include the examples from the (UK) Roman Amphorae database.
To take things a stage further, we can also use the voabularies and mappings to account for differences not only in language, but also granularity in the definitions and classifications used within catalogues. In the example below, you can see two descriptions of "form" from the Italian and Spanish catalogues. In their mappings, colleagues from Pisa and Barcelona have classed these to the AAT term jars
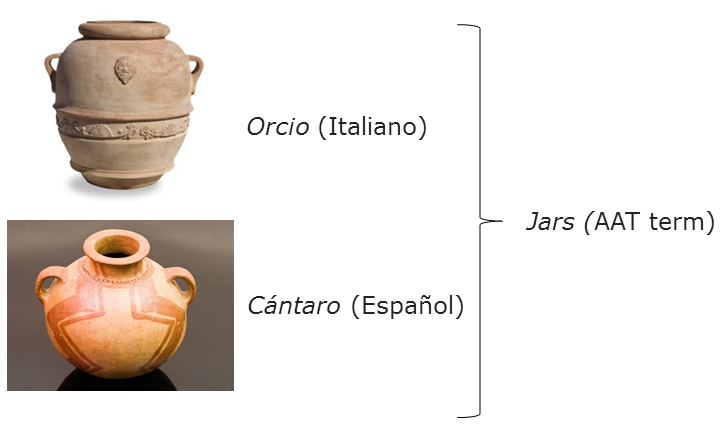
This can be utilised in the ArchAIDE application (below). So, in one instance you may be dealing with a fieldworker that finds part of a vessel. There's enough information for them to begin to establish its form according to the list of AAT terms we're using. The reference database can also provide a preview of what we're calling "jars" to help the user pick a form. In this case, the user is happy that it's probably part of a "jar", in which case the comparison can be weighted towards all those types which have been mapped to this concept (including “Cántaro” or "Orcio"). Thus, the application may be able to tell me (British, with limited understanding of Spanish ceramic typologies!) that I've found something which in Spanish is called a “Cántaro”. Conversely, the user may be more expert in chronologies and typologies of ceramics in their locale, and already be able to recognise a “Cántaro”. In this case the application will allow them to use their native term, which as we know is a "jar" can be used to expand a search. This may be useful as (in this hypothetical case) there may be sub-types of “Cántaro”. Finally, the mapping between "Cántaro" and "jars" means that both terms are stored in the final results.
These are admittedly, small steps and only beginning to use the cababilities of a structured vocabulary such as the AAT (inference for example). However, the work from all contributing partners in mapping the terminologies within their catalogues is not to be underestimated. It is to be hoped that this hard work reaps dividends in allowing the ArchAIDE applicaiton to enrich the potential of sherd-based searches, returning potential matches that would otherwise be hidden by our historic traditions of classification.
